Lab -- Publicly Accessible Datasets
By Dave Eargle
Open data science means that others should be able to rereun your code and replicate your results. The first hurdle to that is making your data pubilcy accessible. I’m ignoring data access rights and terms of use and just talking about streamlining the access ability.
Goals: should be one-click for the user, which means the following are out:
- the user mouting a shared google drive
- the user downloading data from kaggle et al and putting it in a certain working directory
Maybe-viable options include the following:
- Find it in an already-publicy-accessible place
- e.g., OpenML datasets can be direct-downloaded via requesting a special url
- host the data on GitHub.
- Caveat – 25MB (Mb?) filesize limit.
- host the data on a personal cloud storage provider – google drive, dropbox, etc.
- Caveat – some trickery is required to get a direct access link.
- host the data on a cloud computing platform, such as google cloud or aws s3.
- Caveat – requires the code-creator to maintain a cloud computing account. But arguably that’s a fringe positive skill to demonstrate for a data scientists.
Let’s try all!
Already-hosted datasets, such as OpenML or UCI ML
You can use url ‘hacking’ (h@x0r-ing) to extract direct-download links from places where datasets are already hosted, as long as the download link does not require authentication. (You could still programmatically get links that require authentication, but that doesn’t work for Open Data Science without sharing your username-password).
Practice with an OpenML dataset
Let’s try with an OpenML dataset such as the spambase dataset.
-
In a web browser, visit https://www.openml.org/d/44.
-
Look at that dataset page’s url:
We intuit that the dataset id is
44. -
On the dataset’s page, there’s a cute little cloud download icon with “CSV” under it towards the top right of the page. Hover over it to see the link address. The one for this dataset is the following:
https://www.openml.org/data/get_csv/44/dataset_44_spambase.arff
If you click that url, the csv should download.
What is an
.arfffile, you ask? Well, it doesn’t matter, as long as it’s structured tabularly or csv-ily. If you can open the downloaded file in e.g. Excel, it will work forpd.read_csvand the like. So forget about it! -
Right-click it and select “Copy link address” (at least in Chrome, all browsers have something similar).
Paste this url into a new browser tab. If it downloads a csv to your browser, then tada! you have a direct-download link.
-
Imagine you were interested in generalizing the url pattern. Note the URL pattern. It’s something like:
https://www.openml.org/data/get_csv/<dataset_id>/<some_specific_filename>It’s easy enough to generalize where to insert the dataset_id, but I’m nervous about the
<some_specific_filename>. Let’s take a guess though and see if the url works without providing the specific filename – maybe the site’s api will default to providing some default csv for the given dataset. Edit the url to just be the following:https://www.openml.org/data/get_csv/44/
And paste it into a browser. Yay, it works.
Know that some web servers may be picky about url routing – for example, it might not work without a trailing slash. We don’t know what web server openML is using, but we can black-box test it. Try without a trailing slash:
https://www.openml.org/data/get_csv/44
It still works, at least for this site.
What this means is that you could use the above url directly in your script via a call such as:
import pandas as pd pd.read_csv('https://www.openml.org/data/get_csv/44')
Note about sklearn.datasets
The [sklearn.datasets] module has several convenience functions for loading
datasets, including
fetch_openml.
This uses the OpenML api to programmatically find the download url for a given
dataset.
In general, if an API exists, it will be more stable for fetching files than url hacking will be. You should use APIs when stability matters.
We could use the sklearn.datasets.fetch_openml function to download the spambase dataset as follows:
>>> from sklearn.datasets import fetch_openml
>>> spam = fetch_openml(name='spambase')
The data is available under key data:
>>> spam.data.head()
word_freq_make word_freq_address word_freq_all ... capital_run_length_average capital_run_length_longest capital_run_length_total
0 0.00 0.64 0.64 ... 3.756 61.0 278.0
1 0.21 0.28 0.50 ... 5.114 101.0 1028.0
2 0.06 0.00 0.71 ... 9.821 485.0 2259.0
3 0.00 0.00 0.00 ... 3.537 40.0 191.0
4 0.00 0.00 0.00 ... 3.537 40.0 191.0
[5 rows x 57 columns]
This particular dataset was converted to a pandas dataframe, since column names were available:
>>> type(spam.data)
pandas.core.frame.DataFrame
We can pin the version by first inspecting the version of the dataset that was downloaded:
# what version is this?
>>> spam.details['version']
1
And then by modifying our earlier code:
>>> spam = fetch_openml(name='spambase', version='1')
N.B.: sklearn.datasets also has a
fetch_kddcup99
convenience function, which includes the ability to load only 10 percent of the data.
Hosting on your own
If your datasets are not already available publicly somewhere else, you can do one of the following.
Uploading small datasets to github
You can host your own datasets that are < 25 MB on github. For demonstration purposes, I committed the above spambase dataset to github. View it at https://github.com/deargle-classes/security-analytics-assignments/blob/main/datasets/dataset_44_spambase.csv.
I cannot use the above as a direct download link. It would download just what you see in your browser – an html wrapper around the dataset. I need just the dataset!
-
Github provides a convenient
?raw=trueurl argument you can append to get a “raw” file, not-wrapped in html.Append that to the above url, and click it, and see if you get the csv:
Hurray, yes you do.
-
Note the resolved url in your address bar after you click the above link:
We infer that
?raw=trueredirects us to araw.githubusercontent.compath. We could alternatively infer the pattern from the above link, and get the same result in our analytics script. -
Also note that the html-wrapped view of the file has a “raw” button on it, above the dataset to the right. Hover over and inspect where that button would take you:
This url says
/rawinstead of/blob. Click the url and note that it redirects you to the aboveraw.githubusercontent.comlink. You could infer a different workable/rawpattern from the above.
(Working as of 2/16/2021).
Sharing larger datasets from Google Drive or Dropbox
You can manipulate sharing links from Google Drive or Dropbox to get direct download links that you can use in scripts.
Google Drive
Using the browser https://drive.google.com view, I uploaded the spambase dataset to my personal google drive, in a folder I created called “datasets”.
Right-click the file and select “Get link.” In the popup window, change the access rights to be that “anyone with the link” can view. Copy the link to your clipboard. My link looks like this:
https://drive.google.com/file/d/19xCOJyKJ-VSCGL-cM2pwY3fCVw-yzMsM/view?usp=sharing
Our goal is to convert the above into a direct download link. This one is trickier than GitHub’s. When I visit the above link in my browser, I see a promising “download” button on the top right. But I don’t get a url when I hover over it. Ah, Google Drive must be using javascript magic!
When I click on the download button, I notice a new tab open, and then close. Like a ninja I copied the url out of the new tab before it closed, and I got this:
https://drive.google.com/u/0/uc?id=19xCOJyKJ-VSCGL-cM2pwY3fCVw-yzMsM&export=download
This url pattern seems harder to generalize from, but I notice that the id in
the second url is also present in the first url. Taking a guess, I’m crossing my
fingers that the pattern is as simple as the following for all files:
https://drive.google.com/u/0/uc?id=<id_pulled_from_first_url>&export=download
But I need to confirm this!
This SO post says that the url pattern does generalize, with the slightly simpler form as follows:
https://docs.google.com/uc?export=download&id=YourIndividualID
Dropbox
If you get a public “sharing link” for a file in Dropbox and examine the URL, you’ll notice that it looks like this:
https://www.dropbox.com/s/611argvbp5dyebw/HealthInfoBreaches.csv?dl=0
I took a guess and changed the dl=0 at the end to dl=1, and tada it direct-downloaded! Like this:
https://www.dropbox.com/s/611argvbp5dyebw/HealthInfoBreaches.csv?dl=1
Easy enough.
AWS S3
You can create an AWS S3 “bucket” from which you host public datasets. The s3 stands for “simple storage service”. The process to create a bucket is hardly “simple,” but it is one-time. Charges, if any, should be extremely minimal (less than 10 cents a month?).
- Create an AWS account if you don’t have one already
- Navigate to the S3 Service
-
I recommend creating a new bucket if you don’t have one already. Its name must be globally unique across all of S3. I created one using my username, called
deargle-public-datasets.This bucket is intended for open data science replication, so your bucket needs to allow public access. So turn off “Block public access.” I left on other bucket defaults.
However, the above on its own will not make your files publicly accessible. It just makes it so they can be made publicly accessible.
-
On the bucket “Permissions” tab, scroll down to the “Bucket Policy” area. This is the area where you write policies using JSON.
-
Click “Edit,” and paste in the following policy, replacing the value for the “Resource” key with the ARN shown for your bucket immediately above the Edit pane. Leave the trailing
/*at the end of your resource name.{ "Version": "2008-10-17", "Statement": [ { "Sid": "AllowPublicRead", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::deargle-public-datasets/*" } ] }You will get a lot of very scary warnings about how your bucket is now public, public public!. This is desired for our open-data-science use case. Only upload datasets to this bucket that you want the world to have read-access to.
Next:
- Upload your dataset to the bucket
- Navigate to the page for your newly-uploaded file by clicking on the filename.
On the file details page, you can find your file’s “Object URL.”
To test that anyone can access your dataset using this URL, copy-paste this into a browser window in which you are not logged in to AWS (for instance, into an incognito or private browsing window).
If you set the policy correctly, your file should download. This means that you can use this url in your analytics script.
Google Cloud
Similar to AWS S3, Google Cloud also uses ‘buckets’ from which you can host public datasets. Relative to AWS, the process to share files from a GCP bucket is extremely simple.
- Create a GCP account if you don’t have one already
- Open your GCP web console (https://console.cloud.google.com/), and select a project.
- Unlike AWS where s3 buckets are specific to accounts, buckets in GCP are specific to projects
- Proceed to Storage -> Browser in the navigation pane and create a new bucket.
- I created one called
deargle-public-datasets - For “Choose where to store your data,” I left the default.
- For “Choose a default storage class for your data,” I left the default.
- For “Choose how to control access to objects,” I chose Uniform.
- I created one called
-
Read and follow the GCP documentation for Making all objects in the bucket publicly readable. As of 2/20/2021, those instructions are the following:
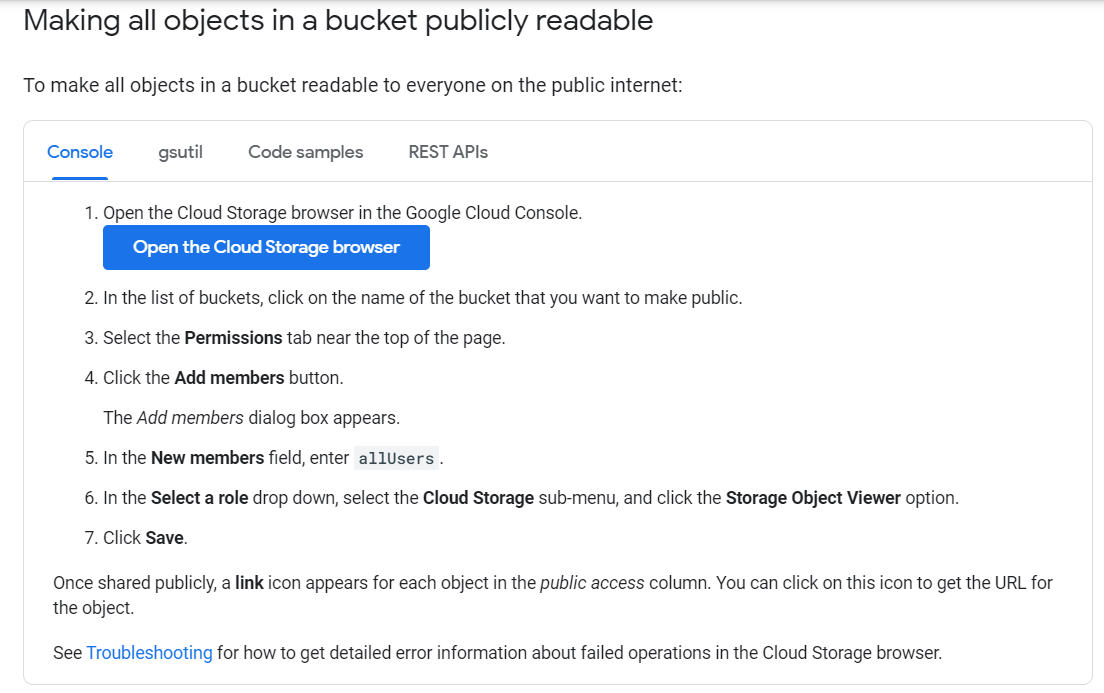
- Ignore all scary warnings about this bucket’s public-ness, past present and future
- Click back to the “Objects” tab and upload your files to your new bucket
- When the upload is complete, click on the file to view object details. You should see a “Public URL” for your dataset. Navigate to this url using a private-browsing window to ensure that your dataset is publicly-available.
- Use this url with
pd.read_csv().
Deliverable
Use this jupyter notebook template.
Follow the instructions in the template notebook to complete and submit your deliverable.